The Bard and The Shell - a great article by Armin Hanisch - @Linkshaender - for the BSD Cafe Journal - @journal
journal.bsd.cafeThe Bard and The Shell – The BSD Cafe Journal
More from  Armin Hanisch
Armin Hanisch

The Bard and The Shell - a great article by Armin Hanisch - @Linkshaender - for the BSD Cafe Journal - @journal
@sirber @joel @dm @sotolf @thedoctor @pixx @orbitalmartian @adamsdesk @krafter @roguefoam @clayton @giantspacesquid @Twizzay @stfn
Nah, even when I have a good wireless, optical mouse in front of me, #CommandLine is #BAE. XD
New #blog post: Why I Love the Command Line
https://rldane.space/why-i-love-the-command-line.html
1081 words
I was grappling with a much heavier subject for a blost, but thankfully, I had this extra little subject in my back pocket, just ready to be picked up and written on much more easily and enjoyably than mental health stuff. ;)
cc: my wonderful #chorus: @joel @dm @sotolf @thedoctor @pixx @orbitalmartian @adamsdesk @krafter @roguefoam @clayton @giantspacesquid @Twizzay @stfn
(I will happily add/remove you from the chorus upon request! :)
The power of LibreOffice
I have many documents created with Microsoft Office for assignments written for graduate school courses years ago. How can I easily convert those dozens of documents to a different format without using an online application? This is an excellent example of the power of open source.
Five years ago I took a course at a local university where all of the documents were provided in ‘docx’ format. Is there a way to convert those documents to an ‘odt’ format? There is and it is quite simple.
$libreoffice --headless --convert-to odt *.docxWhat if I decided I wanted to convert those ‘docx’ items to ‘html’ so they could easily be shared on my classroom website. What if I had wanted to convert all those documents to html?
$libreoffice --headless --convert-to html *.docxI can use the same tool to turn those ‘docx’ files into ‘pdf’ files with an iteration of the same command.
$libreoffice –headless –convert-to pdf *.docx
Using LibreOffice from the command line inside the directory where the files you want to convert is easy and the conversion is accomplished in a matter of seconds depending on your processor and memory. You can find many more uses of LibreOffice from the command line by entering the following command on your own command line if you have LibreOffice installed as most Linux distributions do.
$libreoffice --helpThis is a great example of the power of open source software.
In fairness, that's a culture that the GNOME, KDE, et al. desktop people changed by doing, years ago.
They've had long meaningful names, with more than 1 vowel in, in the desktop applications world for years.
When it comes to nomenclature "st" actually sucks *more* as a name to unfamiliar users than "gnome-terminal". (-:
It's the same sort of deal with the "convenience" aliases versus the full cmdlet names in #PowerShell.
Rethinking CLI Interfaces for AI
https://www.notcheckmark.com/2025/07/rethinking-cli-interfaces-for-ai/

I’ve been playing around with this and I can’t tell you how much I love this cli interface. It’s much easier for me, now, to edit and create new newsletters/emails. I’m super glad this newsletter platform offers this! it’s a lot cleaner, for me, than the web interface. As of right now, there’s a few bugs, but it still works well and i’ve already started contributing to the documentation! Providing some more notes for Windows users and explaining a few things that’s not in the original documentation. Buttondown CLI | Buttondown Documentation https://docs.buttondown.com/buttondown-cli #Cli #CommandLine @buttondownemail @buttondown #Terminal #OpenSource #TUI

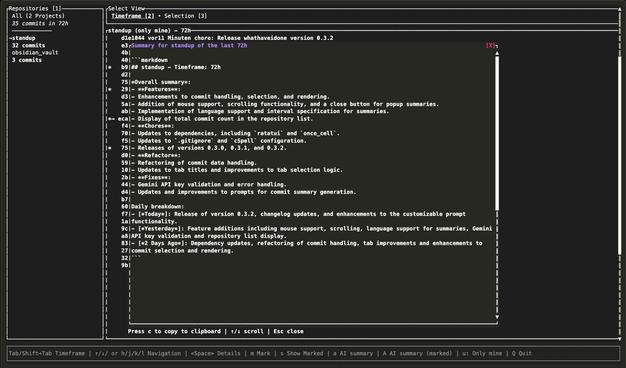
Summarize your GIT commits for standup and time tracking with this TUI Library. Built with #ratatui and #rust.
https://www.flore.nz/blog/whathaveidone-a-git-based-tui-for-forgetful-software-developers/


Determine Which Linux/Unix Init System is Being Used
Join this investigative adventure to determine the init system being used on GNU/Linux or Unix operating system using illustrated command examples.
It's coming. January 2026.
Pre-order now at Barnes & Noble
Hey know what I just discoverec? 'btop' - it's like top, but with color. No not like htop, this has MOAR COLOR AND BARS AND SHIT. It's super-schmexy. This is my mbp rendering a new video file with Adobe Media Encoder.
#mac #adobe #premiere #cpu #dataisbeautiful #top #commandline
Found a handy CLI tool for Git >_
 **git-statuses** — Display the status of multiple Git repositories in a clear, tabular format.
**git-statuses** — Display the status of multiple Git repositories in a clear, tabular format.
 Scans directories recursively for Git repositories
Scans directories recursively for Git repositories
 Written in Rust!
Written in Rust!
The Sequencer: Detect one-dimensional sequences in complex datasets
The Sequencer reveals the main sequence in a dataset if one exists. To do so, it reorders objects within a set to produce the most elongated manifold describing their similarities which are measured in a multi-scale manner and using a collection of metrics. To be generic, it combines information from four different metrics: the Euclidean Distance, the Kullback-Leibler Divergence, the Monge-Wasserstein or Earth Mover Distance, and the Energy Distance. It considers different scales of the data by dividing each object in the input data into separate parts (chunks), and estimating pair-wise similarities between the chunks. It then aggregates the information in each of the chunks into a single estimator for each metric+scale.
https://www.europesays.com/us/18793/ Meta says it’s winning the talent war with OpenAI #ai #Business #CommandLine #Entertainment #Gadgets #Gaming #Meta #OpenAI #SocialMedia #Tech #UnitedStates #UnitedStates #US
Meta says it’s winning the talent war with OpenAI https://www.theverge.com/command-line-newsletter/694028/meta-openai-100-million-bonus-talent-war #Entertainment #CommandLine #SocialMedia #Gadgets #Gaming #OpenAI #Meta #Tech #AI
Meta says it’s winning the talent war with OpenAI https://thever.ge/cVgu #Entertainment #CommandLine #SocialMedia #Gadgets #Gaming #OpenAI #Meta #Tech #AI
Handy #bash #alias to get your phone's battery status from the #CommandLine if you're using #KDEConnect and it's available:
alias kcbatt='qdbus6 org.kde.kdeconnect /modules/kdeconnect/devices/$(grep -Em1 "^\[[0-9a-f_]+\]" ~/.config/kdeconnect/trusted_devices |tr -dc 0-9a-f_)/battery org.kde.kdeconnect.device.battery.charge'
(Will take the device id for the first device in your trusted_devices file. If you have more than one phone registered to #KDE Connect, then you need to add some more logic (and likely make it into a bash function or script))
[Apologies to Ernest Thayer]
I enjoyed this new Zine from @b0rk - "The Secret Rules of the Terminal". I've been using command lines for decades and I still learned a lot.

This is rad. It’s a queer digital zine called New Session that’s published via Telnet.
Co-founder/editor Cara Esten Hurtle notes:
“The project isn’t just retro novelty—it’s a radical rejection of the addictive social media and algorithmic attention-mining that have defined the modern day internet.”
(Hat tip @404mediaco: https://www.404media.co/queer-online-zine-new-session-telnet/)














 GitHub:
GitHub: