
Today in BoneQuest History for March 22nd 2020 "TWO MORE THINGS" https://bonequest.com/7672 #bonequest 
 #9gag #coding #deuce_pants_spigot #drunk_deuce #holocaust #richie_cordell #tiffany #unicode #utf_8
#9gag #coding #deuce_pants_spigot #drunk_deuce #holocaust #richie_cordell #tiffany #unicode #utf_8


Today in BoneQuest History for March 22nd 2020 "TWO MORE THINGS" https://bonequest.com/7672 #bonequest #9gag #coding #deuce_pants_spigot #drunk_deuce #holocaust #richie_cordell #tiffany #unicode #utf_8
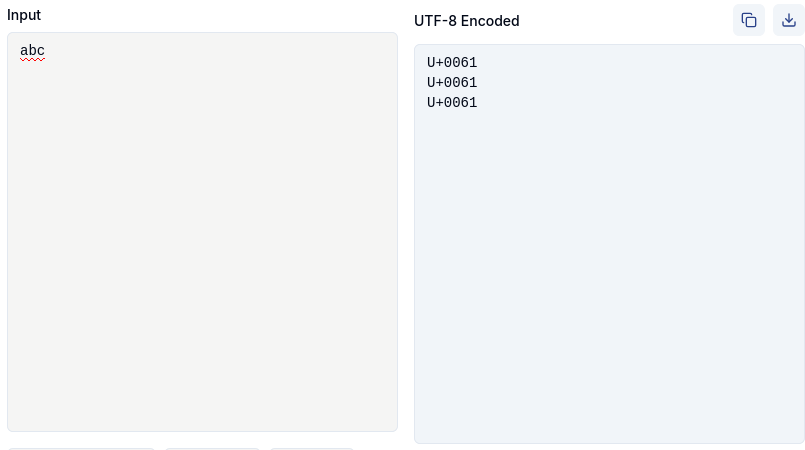
#Unicode is one of those little things in life that I can't help but smile about.
Is it perfect? No, of course not. Is it better than the alternative? Yes, so much so that every time I'm confronted with a long list of character encodings I can choose from, I feel a sense of relief when I find #UTF8 among them.
I wouldn't have thought it possible to standardize a single character encoding for everyone, and yet, somehow, there is just such a standard.
so, yeah, the other thing i want it to do is pop up a waveform display (#braille #unicode, or maybe #sixel? #whynotboth) to let you cut album rips into tracks. gonna need it for the original content too, since some of that is only archived on #youtube by this point...
i already implemented that feature in #tek, now i just gotta copy it over... ugh, i need motivation, and concentration, and medication!
Durdraw 0.29.0 has been released! New features include Durview, (an artpack viewer with 16colo.rs integration), custom character sets, better handling of large files, and more. Check it out at https://github.com/cmang/durdraw

Are your files too small? If so, simply re-encode each bit as one of the Unicode characters 🯰 or 🯱 (U+1fbf0/1, Segmented Digit Zero/One). Your files will be instantly sixteen times bigger, and your self-esteem will come roaring back!
Digital Greek #typography is broken: A petition towards the #Unicode Consortium and software developers to improve standards and fix implementations  https://www.openpetition.eu/gr/petition/online/digital-greek-typography-is-broken-improve-standards-and-demand-fixes-in-all-software
https://www.openpetition.eu/gr/petition/online/digital-greek-typography-is-broken-improve-standards-and-demand-fixes-in-all-software
᳄ claims to be "SUNDANESE PUNCTUATION BINDU LEU SATANGA" (U+1CC4), but I know "Horse goes faster than Segway" when I see it ...
#Unicode
#itch #itch_io #gamedev #devlog #commonLisp #programming
Getting back into that game dev saddle.
Demo successfully shows that *this* *was easy* *for everyone*.
#McCLIM #gui #unicode character world adventure for a
> (unget:unsy '(smiling cat))
""
|#x1F638|
#\GRINNING_CAT_FACE_WITH_SMILING_EYES
I became tired while writing the codes so it's a story told through pictures and a video clip of #emacs.
Encourage me to write it up later. https://lispy-gopher-show.itch.io/lispmoo2/devlog/891545/gui-table-of-unicode-common-lisp-interface-manager-cat-adventure
, a circle (starting location), some tiles (\"ground\") and a black star \"goal location\".
It's in an emacs orgmode src block, of the lightfield default emacs colorscheme. After defining the display-list, I guess it
(run-frame-top-level *game*)s.")

Today I learned that there is a specific #unicode "record separator" symbol, formally known as "U+001E Information Separator Two".
It is meant to be used to indicate a separation between two units of information. An example of where this could be used is in a separated-value file, e.g. a CSV, but using this symbol instead of a comma.
This is interesting because there are vanishingly few instances where the record separator symbol would appear in most contexts, but many instances where a comma appears. Using this symbol instead of a comma (or a semi-colon, or an exclamation point, or any one of the usual separators) could make some data hygiene scenarios much more straightforward.
Hey everyone. I must admit, I don't believe I have ever seen someone enter #utf8 #unicode characters on a #computer in a natural way. Which seems weird, because a bunch of languages use them.
I wrote a #commonLisp #asdf package that just looks up a list of symbols in a file that has every non-surrogate unicode codepoint in it, and an #emacs #elisp function that just calls the #lisp one.
https://codeberg.org/tfw/unicode-chars
Multilingual people, what can you tell me about doing this at all?
)
returning
(\"⍣\" |#x2363| 9059 #\APL_FUNCTIONAL_SYMBOL_STAR_DIAERESIS \"->⍣<-\")
and
(multiple-value-list (unget:unsy '(sta si) '(apl)))
returning
(\"✶\" |#x2736| 10038 #\SIX_POINTED_BLACK_STAR \"->✶<-\")")
Petition to make the  emoji generally work with the ZERO WIDTH JOINER for combined emojis, to put googly eyes on any other emoji.
emoji generally work with the ZERO WIDTH JOINER for combined emojis, to put googly eyes on any other emoji.
Notable example: +
Come on, Unicode Consortium! You cowards.
Hello, I'm an open source software engineer in my late 30s living in #Seoul, #Korea, and an avid advocate of #FLOSS and the #fediverse.
I'm the creator of @fedify, an #ActivityPub server framework in #TypeScript, @hollo, an ActivityPub-enabled microblogging software for single users, and @botkit, a simple ActivityPub bot framework.
I'm also very interested in East Asian languages (so-called #CJK) and #Unicode. Feel free to talk to me in #English, #Korean (#한국어), or #Japanese (#日本語), or even in Literary Chinese (#文言文, #漢文)!
A typographical sin that's been annoying me recently:
#Unicode has a specific code point U+2212 for MINUS SIGN, for use when you mean the mathematical notion of subtraction or negation. Any other uses of a horizontal line have separate code points: hyphens, various lengths of dash, box-drawing characters. You can _tell_ when someone means mathematical minus.
Why would a font deliberately make U+2212 a _different width_ from PLUS SIGN?!
#UserAgent based banning of #textmode browsers is sooooo lame.
$ lynx -useragent= https://[…]
https://[…]
Here are some emojidentifiers for your next Python code:
import math
乁_ツ_ㄏ = None
乁_益_ㄏ = math.nan
def minnums(values: list | 乁_ツ_ㄏ = 乁_ツ_ㄏ):
if (
values is 乁_ツ_ㄏ
or not all(isinstance(n, (float, int))
for n in values)
):
return 乁_益_ㄏ
return min(values)
After a long period of quiet, I have released an update to the `unicode-age` #Python package
https://pypi.org/project/unicode-age/
The package now supports #Unicode 16.0
In the old #ASCII days, you could change a letter between upper and lower case by XORing its character code with 0x20. Of course, if you tried this with anything that wasn't a letter, you'd get nonsense results.
If you try that with #Unicode code points, it sometimes works, and sometimes doesn't. But Unicode can deliver much more impressive nonsense when it doesn't.
A fun example I just found: the "lower-case" version of CAR is NO PEDESTRIANS.
>>> chr(ord(' ') ^ 0x20)
') ^ 0x20)
' '
'
I missed this last year.
The new regime in Syria have a new flag. This means the Emoji representation of 🇸 🇾 needs to change.
Some discussion at
https://github.com/googlefonts/noto-emoji/issues/495
Why stop at simply Anglish?
Let's also bring back Elder Futhark! P.S. there is a unicode block for the runic alphabet.



 ...
... 













 | R.I.P Natenom
| R.I.P Natenom 


