
#computerscience


 Blain Smith
Blain Smith 
Hi! This is my #introduction post here on absturztau.
I'm a lover of #math (I have a video essay on the cardinalities of the naturals and the reals, as well as a complex function visualization tool), #computerscience (it's my major plus have a ton of side projects on my GitHub), and, of course, #gamedev (I was part of the gamedev student group in university and am currently developing a commercial game on my own).
I still have an active account on mathstodon.xyz/@wqferr, but I was told I was really missing out on sharkey (and honestly my prev instance's emotes kinda suck).
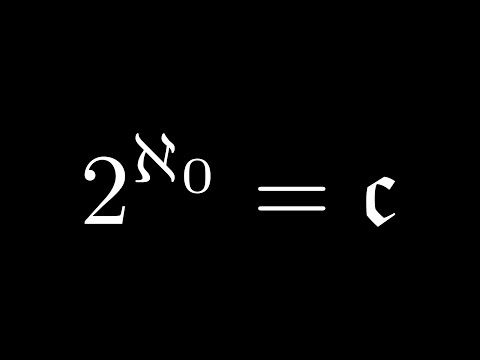

#ComputerScience has some fun names for its fundamental problems: "Byzantine generals", "confused deputy", "dining philosophers", "the halting problem"; what else?

Crunching The News For Fun And Little Profit - Do you ever look at the news, and wonder about the process behind the news cycle? ... - https://hackaday.com/2025/07/09/crunching-the-news-for-fun-and-little-profit/ #computerscience #originalart #literature #featured #interest #news


 StyLo the Unicorn
StyLo the Unicorn 
Here are new fun things caused by #ArtificialIntelligence and politics:
- The university here is going to stop giving computer scientists programming classes. Currently there are still courses for 2 semesters. Anticipating the Impact of AI on the future jobs.
- Schools already stopped offering mandatory computer courses because knowledge would have been ubiquitous. This leads to the problem that 50% of #ComputerScience students never switched on a Computer.
Education in a free fall. 

Breaking: Computer Science is becoming a liberal arts degree. Philosophy majors everywhere: "First time?" 
Universities are scrambling to reinvent CS curricula as AI eliminates entry-level coding jobs. The new focus? Critical thinking and communication over pure programming skills.


Autoformalization of mathematical theorems? No shit!
—
New blog post on Freedom Math Dance
https://freedommathdance.blogspot.com/2025/07/autoformalization-of-mathematical.html

DBLP is super slow / hangs on me, anyone knows if there an issue ?

https://www.europesays.com/2210654/ The data visualization and intelligent text analysis for effective evaluation of English language teaching #AppliedMathematics #ComputationalScience #COMPUTERSCIENCE #Data #DataVisualizationAnalysis #EffectEvaluation #EnglishLanguageTeaching #EnsembleLearning #HumanitiesAndSocialSciences #InformationTechnology #IntelligentTextAnalysis #MathematicsAndComputing #multidisciplinary #PureMathematics #science #ScientificData #Software #statistics


Came across Seymour Papert's "Teaching Children Thinking" essay:
https://citejournal.org/volume-5/issue-3-05/seminal-articles/teaching-children-thinking]
(thanks @ColinTheMathmo for the better link)
It captures almost exactly my philosophy of education, teaching, computing, and so on.
I want to quote so much of it! Here's just one:
"The purpose of this essay is to present a grander vision of an educational system in watch technology is used not in the form of
machines for processing children but as something the child himself will learn to manipulate, to extend, to apply to projects, thereby gaining a greater and more articulate mastery of the world, a sense of the power
of applied knowledge and a self-confidently realistic image of himself as an intellectual agent."
I'm surprised at how the article -- from 1971! -- describes so many of the programming-like things available today. So much of the play-oriented things we have now -- games like Robot Turtles, various robots that do path-following things -- are exactly what they were doing over half a century ago.

Fedi, I have a #ComputerScience (maybe #Linguistics ?) Question I need your lovely guidance for 


I have a design problem about grammar ambiguity ish stuff and want to find reading, resources or theory I can check out to come up with an elegant solution.
Particularly, I'm trying to find good alternatives to cases when a given word can appear in multiple parts of the syntax
An example problem (sorry it's very computery): I have two strings (or lists of tokens) I need to combine into a single string, separated by a delimiter, such that both strings can be retrieved again. But, that delimiter can show up in either of the two strings. The standard way to deal with this is to designate an escape token and prepend all instances of the delimiter within the strings with it (eg \"). The issue there is now is that any instances of the escape token need escaping too (e.g. \\).
Slightly less work is inserting a repetition of the delimiter any non-delimiting instances of the token. If the delimiter appears twice, it's part of a string, and the only non-repeating delimiter must be the real one. This can look ugly if the delimiter is long though.
Another crazy option would be interlacing the two strings so all even tokens belong to string 1 and odd ones are string 2. This would obviously look horrible, but maybe there are other solutions taking a similar thought process.
That's just the most basic case I'm interested in, there might be heaps of other strategies when you have more restrictions and guarantees on what the tokens might contain.
So yeah I'm looking for stuff like that so I can figure out good patterns for unambiguous yet elegant grammars. For a tad more context, I'm thinking about command line argument formats, trying to think of the most user friendly ways to handle complex data as a list of arguments.
Also please boost and let me know if there's hashtags I should include etc  #CompSci #programming #askfedi #TechSupport #CompSci #programming #askfedi #TechSupport
#CompSci #programming #askfedi #TechSupport #CompSci #programming #askfedi #TechSupport

Hi I’m Annika! 28F and here’s my #introduction!  Cat mom.
Cat mom.  Epicurean.
Epicurean.  Showerhead balladeer.
Showerhead balladeer.
 The defiant lab rat in God’s pristine research facility.
The defiant lab rat in God’s pristine research facility.
 I want to revive my interest in:
I want to revive my interest in:
#art ✦ #books ✦ #typography ✦ #poetry ✦ #film
 My current interests are:
My current interests are:
#psychology ✦ #selfdevelopment ✦ #spirituality ✦ #highstrangeness ✦ #pkm ✦ #heutagogy ✦ #systemsdesign ✦ #revops ✦ #frontendwebdev ✦ #devops
 I have a background in:
I have a background in:
#graphicdesign ✦ #instructionaldesign ✦ #businessprocessanalysis ✦ #ecommerce ✦ #computerscience
Excited to be sharing this space with you!

 Huge congratulations to Indian-origin professor Eshan Chattopadhyay for winning the 2025 Gödel Prize!
Huge congratulations to Indian-origin professor Eshan Chattopadhyay for winning the 2025 Gödel Prize!  Alongside David Zuckerman, his groundbreaking work on randomness extraction is revolutionizing secure computing, from credit cards to military systems. An IIT Kanpur alumnus shining bright at Cornell!
Alongside David Zuckerman, his groundbreaking work on randomness extraction is revolutionizing secure computing, from credit cards to military systems. An IIT Kanpur alumnus shining bright at Cornell!
#GödelPrize #ComputerScience #IndianExcellence
https://www.indiatoday.in/world/us-news/story/indian-origin-professor-eshan-chattopadhyay-wins-godel-prize-for-computer-science-research-iit-kanpur-alumnus-2742213-2025-06-17
#ComputerScience #Teaching #PartTime

...
Support Embedded( https://embedded.fm/support ) and get an invite to join the slack.
#embedded #engineering #machinelearning #ml #datascience #ai #bookclub #reading #signalprocessing #slack #math #mathematics #computerscience #embeddedengineer #stemeducation #slack
2/2

I was browsing over this research paper by Toby Ord who talks about comparing an LLM working on a lengthy task as compared to a human working on the same lengthy task. The longer it takes to complete the task, the greater the odds of failure for the LLM, in fact the odds of failure increase exponentially with time. Naturally, larger LLMs with more computing power can go for longer, but the exponential odds of failure with respect to time trend are the same no matter what.
So for example you might be able to get the LLM to work on a task for 1 hour with a 8-billion parameter model and expect it will succeed at the task 50% of the time. Maybe you can get 2 hours out of a 16-billion parameter model where you can expect it will succeed at the task 50% of the time (I am guessing these parameter sizes). But after that “half life” the odds of the LLM succeeding taper-off to zero percent.
I haven’t read the little details yet, like how do you judge when the task is done (I presume when the LLM claims that it has finished the job), or do these tests allow multiple prompts (I presume it is just fed an input once and allowed to churn on that input until it believes it is finished). So that makes me wonder, could you solve this problem, increase the AI’s rate of success, if you combine it with classical computing methods? For example, perhaps you can ask the LLM to list the steps it would perform to complete a task, then parse the list of steps into a list of new prompts, then feed-back each of those prompts to the LLM again, each one producing another list of sub tasks — could you keep breaking-down the tasks and feeding them back into the AI to increase it’s odds of success?
It is an interesting research question. I am also interested to see how much energy and water this takes as compared to a human working on the same task, including the caloric intake of food, and perhaps the energy used to harvest, process, and deliver the food.

This is for the super nerds, so don't feel bad if you don't get it.
I asked ChatGPT to design a menu with Dutch food influences for an Edsger W. Dijkstra-themed restaurant based upon his work. I then asked it to create the LaTeX code to generate a printable version of the menu.
No notes. Perfection. Lost in the PDF generation was that drinks were labeled as “Side Effects (Handled)" which is divine.

Knowing a language doesn’t always equal knowing what to build.
Think Like a Programmer helps bridge the gap between syntax and strategy—so you can learn to think your way through the hard parts.
Available as part of our Coding for the Curious Humble Bundle supporting @eff : https://www.humblebundle.com/books/coding-for-curious-no-starch-books

ISO people familiar with reversible computing — specifically, I'm interested in understanding skepticism towards it (either in terms of theory or implementation)
thanks for boosting 
...
Join the Embedded Slack( https://embedded.fm/support ), support Embedded, and be a part of this learning experience.
Come let's read and learn together!
#embedded #engineering #machinelearning #ml #datascience #ai #bookclub #reading #signalprocessing #slack #math #mathematics #computerscience #embeddedengineer #stemeducation #slack
2/2