
PSA for #Rstats from the R NEWS RSS stream: Let's all cite the new DOI for the R manuals.

#rstats
15 posts15 participants0 posts today
Replied to Danielle Navarro

@djnavarro I expect everyone reading this (except for me a few minutes ago) knows this, but if you do this sort of thing:
```
---
format:
html:
theme:
light: litera
dark: darkly
---
```
you get a button at the top of the document that enables the reader to select between the two modes. Source: https://mine-cetinkaya-rundel.github.io/quarto-tip-a-day/posts/17-dark-mode/. #rstats

A Quarto tip a dayDark mode – A Quarto tip a dayInspired by the saying “An apple a day keeps the doctor away”, this project titled “A Quarto tip a day keeps the docs away” is a playful attempt to share Quarto tips for a month leading up to my rstudio::conf(2022) keynote on Quarto.

Parallel processing FTW #RStats

Step 1: Write R code
Step 2: Share it
Step 3: Spend 2 hours helping someone install R and troubleshoot their environment
OR
Step 1: Write R code
Step 2: webR sharelink
Step 3: Profit 
Continued thread

Update to this situation. For some reason, I didn't read my Rmd document all the way through (there is a lot of stuff, I was interested in parts of it, and restarting it), and it turns out that I saved the whole dang set of objects to an #RStats RData file!
So at least I have all the objects using in the analysis!
Will see how much that actually helps tomorrow.




#RStats {patchwork} is the bees knees


 A team from the Mind, Brain and Behavior Research Center (CIMCYC, cimcyc.bsky.social) published a #programming guide aimed at students in #psychology and #cognitive #neuroscience. This evolving set of #tutorials offers a curated collection of conceptual reflections, practical examples, and methodological recommendations. The material is available in #Python, #RStats, and #MATLAB.
A team from the Mind, Brain and Behavior Research Center (CIMCYC, cimcyc.bsky.social) published a #programming guide aimed at students in #psychology and #cognitive #neuroscience. This evolving set of #tutorials offers a curated collection of conceptual reflections, practical examples, and methodological recommendations. The material is available in #Python, #RStats, and #MATLAB.
 https://wobc.github.io/programming_book/
https://wobc.github.io/programming_book/
#CognitiveScience #OpenScience

Absolutely thrilled our open-source demand model won the Florence Nightingale Award!
 Proud to be part of a brilliant, kind, and thoughtful team at The Strategy Unit who value #opensource, probabilistic thinking & delivering public value.
Proud to be part of a brilliant, kind, and thoughtful team at The Strategy Unit who value #opensource, probabilistic thinking & delivering public value.

 Explore the code: https://github.com/The-Strategy-Unit/nhp_model
Explore the code: https://github.com/The-Strategy-Unit/nhp_model
 Happy to chat if you want to know more
Happy to chat if you want to know more

 New R package: forestdata makes it easy to download forestry and land cover data from multiple sources (Copernicus, ESRI, EU-Trees4F, and more). Supports sf, SpatRaster, and tidy outputs.
New R package: forestdata makes it easy to download forestry and land cover data from multiple sources (Copernicus, ESRI, EU-Trees4F, and more). Supports sf, SpatRaster, and tidy outputs.
Explore it here: https://cidree.github.io/forestdata/


"510 years of professional experience in data science" how can I lie on that one 
"I am Defuneste of the Clan #Rstats I was born in 1518 in the village of Glenfinnan since them I wrangled data. And I am immortal."

#Statistics #RStats #AcademicChatter people, what is a nice, citable (statistical) simulation study that you like? For example, comparing methods or data analysis approaches.
(self-promotion definitely allowed)


Finally had a good enough reason to set up an R-Universe for official work #RStats packages. It's so nice to use behind the scenes and makes it so much easier for users that aren't familiar with Git and other devtools to just install binaries. @jeroenooms, thank you for your hard work on this.
aagi-aus.r-universe.devR packages by aagi-aus
Well crap. A project from over 5 years ago, when I wasn't doing things well, and I've not got package versions recorded, and was doing all of the analysis via a `knitr` script, with very few intermediates saved.
And now collabs have reviewer comments, and want to change some outputs.
The package is under a git repo, but figuring out how far back to go is a pain in the butt.
So glad using `renv` now at least gives me a record of what versions I had at the time of analysis. #RStats

burnt echoes in #rstats

Useful paper investigating the precision of various #reliability and #MeasurementError parameters under different conditions and study designs:
https://link.springer.com/article/10.1007/s10742-022-00293-9
It comes with an #RStats shiny tool to explore some of these oneself:
https://iriseekhout.shinyapps.io/ICCpower/
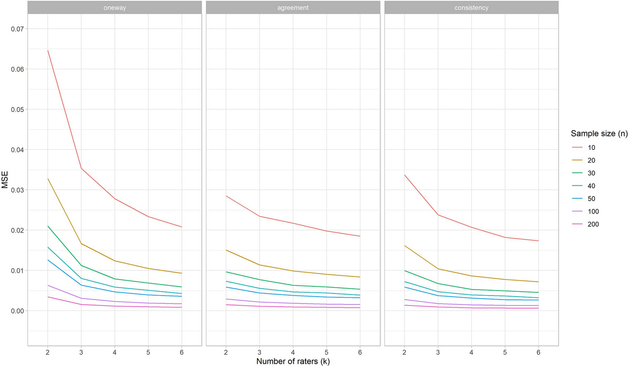
SpringerLinkSample size recommendations for studies on reliability and measurement error: an online application based on simulation studies - Health Services and Outcomes Research MethodologySimulation studies were performed to investigate for which conditions of sample size of patients (n) and number of repeated measurements (k) (e.g., raters) the optimal (i.e., balance between precise and efficient) estimations of intraclass correlation coefficients (ICCs) and standard error of measurements (SEMs) can be achieved. Subsequently, we developed an online application that shows the implications for decisions about sample sizes in reliability studies. We simulated scores for repeated measurements of patients, based on different conditions of n, k, the correlation between scores on repeated measurements (r), the variance between patients’ test scores (v), and the presence of systematic differences within k. The performance of the reliability parameters (based on one-way and two-way effects models) was determined by the calculation of bias, mean squared error (MSE), and coverage and width of the confidence intervals (CI). We showed that the gain in precision (i.e., largest change in MSE) of the ICC and SEM parameters diminishes at larger values of n or k. Next, we showed that the correlation and the presence of systematic differences have most influence on the MSE values, the coverage and the CI width. This influence differed between the models. As measurements can be expensive and burdensome for patients and professionals, we recommend to use an efficient design, in terms of the sample size and number of repeated measurements to come to precise ICC and SEM estimates. Utilizing the results, a user-friendly online application is developed to decide upon the optimal design, as ‘one size fits all’ doesn’t hold.
How good is Mitchell O'Hara-Wild's {vitae} package for #RStats, https://mitchelloharawild.com/blog/vitae/? I managed to add a whole new section to my CV (https://codeberg.org/adamhsparks/AHSparks_CV) without screwing up formatting of the final document this morning. Thanks, Mitchell!
mitchelloharawild.comMitchell O’Hara-Wild - Introducing vitaeAutomate your CV with vitae


After a longer than intended break, episode 207 of the @rstats @rweekly Highlights podcast is out! https://serve.podhome.fm/episodepage/r-weekly-highlights/207
 Generating Quarto syntax within R @djnavarro
Generating Quarto syntax within R @djnavarro  Introduction to Behavior-Driven Development (Jakub Soboleqski)
Introduction to Behavior-Driven Development (Jakub Soboleqski) Dive()ing into the hunt @milesmcbain
Dive()ing into the hunt @milesmcbain
Plus one of your hosts could not resist a hot take or two!
h/t @mike_thomas & @R_by_Ryo 

R Weekly HighlightsIssue 2025-W28 HighlightsIt's been far too long since our last episode of R Weekly Highlights, but we are finally back with episode 207! In this episode we learn about novel ways…

f you use ggplot2, you will find patchwork package amazing https://patchwork.data-imaginist.com/ #rstats
I track @stratosphere's posts & their bot has a daily top 10 sketch IPs list. My kept  lots of "*.100" IPs & I was curious how frequently they showed up.
lots of "*.100" IPs & I was curious how frequently they showed up.
Went back 200 posts w/GH:McKael/madonctl using both R and DuckDB.
Def block these.
— #DuckDB: https://ray.so/SdMcBZa
— #RStats: https://ray.so/naTBBMS